Ollama est un outil à code ouvert, prêt à l’emploi et permetant d’intégrer un modèle de langage de façon transparente, que ce soit en local ou depuis votre propre serveur. Du coup, que vous soyez développeur, chercheur ou passionné d’IA, Ollama vous offre une alternative puissante tout en évitant d’utiliser des versions payantes d’API commerciales.
Dans ce tutoriel, nous allons voir comment installer Ollama sur votre machine et comment l’utiliser efficacement.

Pourquoi utiliser Ollama ?
Ollama présente de nombreux avantages qui en font une solution particulièrement attrayante pour ceux qui souhaitent exploiter l’intelligence artificielle en local :
- Un environnement isolé évite tout conflit potentiel avec d’autres logiciels installés
- Gestion locale des modèles IA : permet de télécharger, de mettre à jour et de supprimer facilement des modèles sur votre système.
- Support multi-plateforme : large prise en charge de diverses plateformes, notamment macOS, Linux et Windows.
- Une facilité d’utilisation : possède une interface en ligne de commande intuitive, prend également en charge des outils GUI tiers, tels que Open WebUI
- Il est open-source : son code accessible et modifiable par la communauté.
Installation d’Ollama
1. Prérequis
La première étape pour installer Ollama consiste à s’assurez d’avoir :
- Un système d’exploitation Windows, macOS ou Linux.
- Une connexion Internet pour télécharger les fichiers nécessaires.
Vous devez vous assurer que votre système répond aux normes minimales pratiques. Il s’agit notamment de disposer d’un processeur Intel/AMD prenant en charge AVX512 pour des calculs efficaces. En outre, il est recommandé d’avoir une mémoire supérieure à 8Go pour gérer efficacement les demandes de calcul. La disponibilité d’environ 50 Go d’espace disque est essentielle pour les opérations d’Ollama et le stockage des données. Bien qu’un GPU ne soit pas obligatoire, il est conseillé pour améliorer les performances, en particulier si vous souhaitez exécuter des modèles 7B ou plus.
2. Installation sur Windows
Via le programme d’installation :
-
Téléchargez le fichier d’installation depuis le site officiel : ollama.com
-
Exécutez l’installateur et suivez les instructions.
-
Une fois l’installation terminée, ouvrez PowerShell et testez avec :
ollama --version
Si tout est correct, vous verrez la version installée d’Ollama. Par contre, si vous voyez une erreur, il est possible que le chemin de Ollama n’a pas été automatiquement ajouté aux variables d’environement. Vous devrez donc le faire manuellement en suivant les étapes suivantes :
- Cliquez avec le bouton droit de la souris sur l’icône de l’ordinateur sur votre bureau.
- Choisissez
Propriétés, puis naviguez jusqu’àParamètres système avancés. - Cliquez sur
Variables d'environnement. - Dans Variables utilisateur pour “votre_utilisateur”, insérez le chemin d’accès absolu au répertoire dans lequel vous prévoyez de stocker tous les modèles. Par exemple :
Variable : OLLAMA_MODELS
Valeur : D:\votre_chemin\models
“votre_chemin” représente ici le chemin d’installation de Ollama sur votre machine. Et le tour est joué ! Vous n’avez plus qu’à lancer vos modèles localement.
3. Installation sur macOS
Via Homebrew :
Ouvrez le terminal et exécutez la commande suivante :
brew install ollama
Vérifiez l’installation avec :
ollama --version
4. Installation sur Linux
Via le script officiel :
Téléchargez et exécutez le script d’installation :
curl -fsSL https://ollama.com/install.sh | sh
Testez votre installation avec :
ollama --version
Utilisation d’Ollama
1. Télécharger un modèle IA
Ollama permet d’utiliser différents modèles. Pour télécharger un modèle, utilisez la commande :
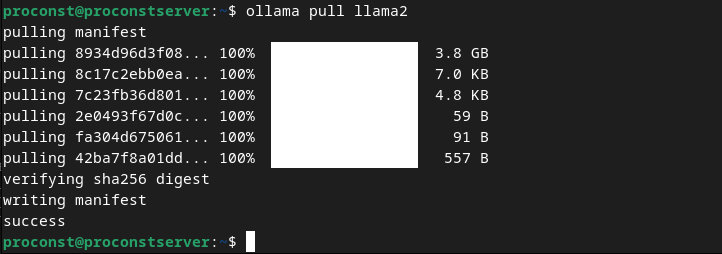
ollama pull llama2
Cela téléchargera et installera LLaMA 2, l’un des modèles les plus populaires, entraîné sur 2 trillions de tokens et prenant en charge, par défaut, une longueur de contexte de 4096.
Sur le site ollama.com/library”, vous trouverez de nombreux modèles prêts à être téléchargés, disponibles dans différentes tailles de paramètres. Avant de télécharger un modèle localement, vérifiez que votre matériel dispose de suffisamment de mémoire pour le charger. A des fin de test, il est conseillé d’utiliser de petits modèles étiquetés 7B qui sont adéquats pour une intégration dans des applications.
A ceux qui ont des ressources encore plus limitées, je conseille plutôt d’utiliser le modèle llama3.2:1b
Ce modèle est plus léger, consomme moins de mémoire et est plus rapide sur les machines avec peu de puissance CPU/GPU, tout en offrant des performances acceptables pour de nombreuses tâches basiques.
2. Exécuter un modèle en local
Une fois le modèle téléchargé, vous pouvez l’utiliser avec :
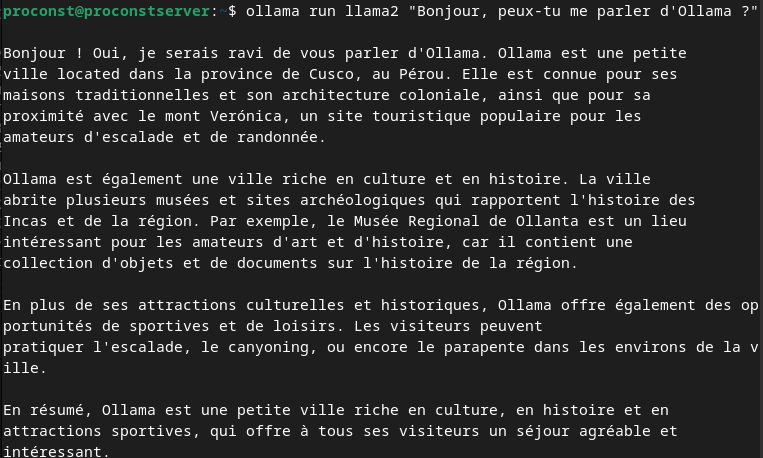
ollama run llama2 "Bonjour, peux-tu me parler d'Ollama ?"
Ollama exécutera le modèle et affichera une réponse basée sur votre requête.
3. Utiliser Ollama en mode interactif
Vous pouvez lancer Ollama en mode conversationnel :
ollama run llama2-uncensored:7b
Puis, entrez vos questions directement dans le terminal.

4. Créer un modèle personnalisé
Ollama permet aussi de personnaliser des modèles en local. Voici un exemple pour créer un modèle basé sur llama2 avec des instructions spécifiques :
ollama create virtualayersmodel --from llama2 --system "Tu es un assistant spécialisé en finance."
Vous pouvez ensuite l’exécuter avec :
ollama run virtualayersmodel "Comment fonctionne la bourse ?"
Et voilà ! Ollama est un outil puissant pour exécuter des modèles d’IA en local, sans dépendance aux services cloud. Avec son installation simple et son interface intuitive, il offre une solution efficace pour tester et déployer des modèles d’intelligence artificielle sur votre propre machine. Et vous ? Quel modèle comptez-vous tester avec Ollama ?
Restez connectés et surtout rendez-vous dans le prochain article pour plus de tutos pratiques. ✌️